Your AI Agent Is Failing Because of Context, Not the Model
Section titled “Your AI Agent Is Failing Because of Context, Not the Model”Photo by Keren Fedida on Unsplash
Non-members can read the story using the link here
One thing that I would say with my many years of experience in building AI systems is that Contexts are underrated. It is clearly affecting the way your RAG or AI Agents perform.
We spend so much time obsessing over model architectures, parameter counts, and training data. But here’s what nobody tells you:
The most powerful model in the world is useless if AI can’t understand what you’re actually asking for.
Context engineering is the invisible architecture that makes AI actually work. It’s the art and science of translating messy human intentions into something machines can understand and process.
But Context engineering isn’t new.
Most people think it was with ChatGPT and prompt engineering. In fact, context engineering is what we have been doing since the 90s. Back then, the researchers were asking the exact same questions we’re asking now: how do you make machines understand what humans really want?
Context engineering isn’t some breakthrough innovation for 2023. It’s the same fundamental problem that we’ve been wrestling with for decades. We’ve just got better hardware now, and that is changing the game.
This blog would take you through the evolution of context-aware computing in the 1990s, RAG systems and multi-agent systems, and the modal patterns, trade-offs, and engineering practices that actually work when you’re trying to ship AI systems that work.
Table of Contents:
Section titled “Table of Contents:”· So What Actually Is Context Engineering?
· The Real Problem: Machines Can’t Read Between the Lines
· Four Eras, One Problem:
∘ Era 1.0: The Dark Ages of “Please Format Your Input Correctly” (1990s–2020)
∘ Era 2.0: The Age of “Wait, It Actually Understands Me?” (2020–Present)
∘ Era 3.0: The Future Where Machines Actually “Get It” (Coming Soon)
∘ Era 4.0: When Machines Know Us Better Than We Know Ourselves
· The Great Reversal: When Humans Stopped Speaking the Machine Language
∘ Era 1.0: The Age of Human Adaptation (1990s-2020):
∘ Era 2.0: The Great Reversal (2020-Present):
· How to manage Context?
∘ Textual Context Processing (How should raw text context be processed to get the best results?)
∘ Multi-Modal Context Processing
· How to Organise the Context collected?
∘ 1. Memory Management
∘ 2. Context Isolation
· Context Abstraction (How to Compact the Stored Context?)
∘ 1. Using Hierarchical Memory Architectures
∘ 2. Adding Natural-Language Summaries
∘ 3. Extracting Key Facts Using a Fixed Schema
∘ 4. Compressing Context into Semantic Vectors
· How to use the Context Effectively?
∘ 1. Intra-System Context Sharing
∘ 2. Cross-System Context Sharing
· Context Selection for Understanding (What context should be selected?)
· How to preserve and update the Context over time?
∘ Challenge I: Storage Bottlenecks
∘ Challenge II: Processing Degradation
∘ Challenge III: System Instability
∘ Challenge IV: Difficulty of Evaluation
· Engineering Practices for Effective Context Engineering
∘ KV Caching
∘ Tool Design
∘ Context Contents
∘ Multi-Agent Systems
∘ Small but Useful Tricks
· Closing Thoughts:
So What Actually Is Context Engineering?
Section titled “So What Actually Is Context Engineering?”Here’s where people usually get it wrong. They’ll tell you context engineering is about “ crafting better prompts ” or “ optimizing your ChatGPT conversations.”
Nope.
Context engineering is the systematic process of designing and optimizing how we collect, store, manage, and use contextual information so machines can actually understand what the hell we want them to do.
If you noticed something missing… like LLMs, GPTs, that’s intentional.
Whether you’re working with a 1995 context-aware system that could barely detect your GPS coordinates, or you’re fine-tuning Claude’s memory architecture, the core challenge is one: bridging the gap between messy human intentions and structured machine understanding.
The Real Problem: Machines Can’t Read Between the Lines
Section titled “The Real Problem: Machines Can’t Read Between the Lines”Think about how humans communicate. Someone tells you, “I’m hungry” and your brain doesn’t just process two words. You’re instantly inferring they want food recommendations, anticipating the conversation might shift to restaurants, noting that maybe this meeting should wrap up soon, considering whether they’re the hangry type you need to handle them carefully
This is what cognitive scientists call “entropy reduction”. We’re filling in gaps, making inferences, and reducing ambiguity using shared context and social intelligence.
We are good at this because we have been doing it for decades. But machines…. They are terrible at this.
Context engineering is fundamentally about entropy reduction. It is taking high-entropy inputs (ambiguous human language, incomplete information, conflicting signals) and transforming them into low-entropy representations that silicon-based systems can process.
This is the “ cognitive gap ” we’re trying to bridge. Carbon-based intelligence (us) versus silicon-based intelligence (them).
What makes it fascinating now? The gap is narrowing. Fast. I mean, really really fast.
Four Eras, One Problem:
Section titled “Four Eras, One Problem:”The context engineering could be broken into four distinct eras according to this research paper.
Era 1.0: The Dark Ages of “Please Format Your Input Correctly” (1990s–2020)
Section titled “Era 1.0: The Dark Ages of “Please Format Your Input Correctly” (1990s–2020)”The machines back then were, how do I put this kindly?… impressively dumb.
They could read GPS coordinates (if you formatted them exactly right), recognize simple patterns you’d explicitly programmed, and execute predetermined logic without deviation
They absolutely could not understand natural language, handle ambiguity, infer anything you didn’t explicitly state or adapt to unexpected situations.
In this era, we were intentional translators. We couldn’t just tell a computer “remind me to call Mom”. We had to decompose that simple human thought into:
IF current_time == 17:00AND current_day == "Sunday"AND user_location == "home"THEN trigger_notification("Call Mom")Our input need to be structured with zero room for interpretation.
The architectural breakthrough came from Anind Dey’s Context Toolkit in 1999. It introduced these concepts:
- Context Widgets: Modular components that collected specific types of context
- Interpreters: Systems that translated raw sensor data into meaningful information
- Aggregators: Tools that combined multiple context sources
Well, it sounds familiar, right? Well, it should. We’re still using these exact architectural patterns in modern RAG systems.
But Era 1.0 taught us that you need separation of concerns in context engineering. Collect separately. Process separately. Use separately. This principle still holds… even today.
Era 2.0: The Age of “Wait, It Actually Understands Me?” (2020–Present)
Section titled “Era 2.0: The Age of “Wait, It Actually Understands Me?” (2020–Present)”Then November 2022 happened.
ChatGPT got dropped, and everything changed overnight. I remember my first conversation with it. I typed a casual question about Python decorators and it just… got it. No formatting requirements. No rigid syntax. Plain English.
My immediate thought: “Oh. This is different.”
Because suddenly machines could parse natural language (actually parse it, not just keyword match), infer implicit intent, handle ambiguous input, and reason across multiple steps and remember conversation context.
We shifted from context-aware to context-cooperative.
The difference is profound. Era 1.0 systems reacted. “You’re in the office, so I’ll silence your phone”. Era 2.0 systems collaborate. “You’re writing a research paper about reinforcement learning. Based on your previous paragraphs and current direction, here’s a suggested structure for your next section.”
Context in Era 2.0 looks completely different:
- Natural language: “Hey, can you help me debug this vector similarity search?”
- Multi-turn history: The system remembers our entire conversation
- Retrieved documents: RAG pulls relevant information from knowledge bases
- Tool APIs: LLMs can invoke external functions
- Memory systems: Persistent user preferences and learned patterns
But here’s the catch. (and this is where it gets interesting)…
The nature of our work hasn’t disappeared. It’s shifted. In Era 1.0, we spent all our energy translating intentions into structured formats. In Era 2.0, we spend our energy on:
- Context selection: What information actually matters?
- Memory management: What should persist versus what should fade?
- Prompt engineering: How do we guide reasoning effectively?
- Retrieval strategy: Which documents are actually relevant?
Different problems. Same underlying challenge: bridging the cognitive gap.
The truth is, we have gone from “not enough context” in Era 1.0 to “too much context” in Era 2.0.
Era 3.0: The Future Where Machines Actually “Get It” (Coming Soon)
Section titled “Era 3.0: The Future Where Machines Actually “Get It” (Coming Soon)”Now we’re getting speculative, but this is where things get really interesting.
Imagine AI systems that understand context the way humans do. Not just processing words, but reading tone of voice and emotional subtext, facial expressions and body language, social dynamics and unspoken expectations, cultural context and situational nuance
They won’t just parse your request. They’ll understand what you meant, what you’re feeling, and what you probably need (even if you didn’t say it).
In Era 3.0, interaction becomes genuinely collaborative; machines act as knowledgeable peers, not tools. Context flows bidirectionally and naturally**,** and most context engineering becomes invisible.
It would be like working with an experienced colleague who just gets you. You don’t have to explain everything. They anticipate needs. They fill in gaps. They challenge your assumptions constructively.
That’s Era 3.0. Much of what we’re doing today like the careful prompt crafting, the memory system design, and the retrieval optimization, will become obsolete. The machine will handle entropy reduction internally.
Our job description changes from “context engineer” to maybe context collaborator or Context negotiator.
I’m not sure yet. But the transition is coming faster than most people realize.
Era 4.0: When Machines Know Us Better Than We Know Ourselves
Section titled “Era 4.0: When Machines Know Us Better Than We Know Ourselves”Okay, bear with me here because this gets philosophically weird.
What happens when AI doesn’t just understand your context, it understands you better than you understand yourself?
Era 4.0 is where the traditional relationship inverts.
Instead of you providing context to machines, machines start actively constructing context for you. They reveal patterns in your behavior you haven’t noticed. They uncover needs you haven’t articulated. They guide your thinking in ways you couldn’t have predicted.
We’re already seeing hints of this, remember AlphaGo? It didn’t just beat Lee Sedol at Go. It taught human players completely novel strategies. A 3,000-year-old game, and the machine found strategies humans had never discovered.
The machine became the teacher. If an AI system can see patterns in your decision-making, emotional responses, and cognitive biases that you can’t see, who’s engineering whose context?
Think about it:
- Your fitness tracker already knows your activity patterns better than you do
- Recommendation algorithms understand your preferences in ways you might not consciously recognize
- AI coding assistants detect patterns in your programming style that you execute unconsciously
Now extrapolate that to every aspect of human cognition and decision-making.
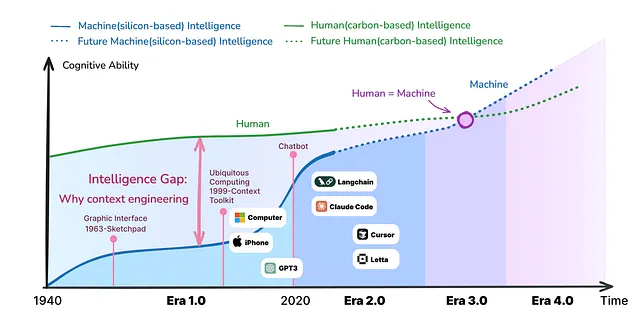
Trajectories of carbon-based and silicon-based cognitive abilities over time — [ Source ]
I’m genuinely uncertain whether Era 4.0 represents liberation or loss of agency. Maybe both? We might gain incredible insights into ourselves while simultaneously depending on machines to help us understand our own minds.
That’s… not dystopian exactly. Just strange and liminal to me.
The Great Reversal: When Humans Stopped Speaking the Machine Language
Section titled “The Great Reversal: When Humans Stopped Speaking the Machine Language”After diving deep into this research, one pattern emerged so clearly it felt like getting slapped in the face with a history textbook.
More machine intelligence = Greater context-processing ability = Lower human-AI interaction cost
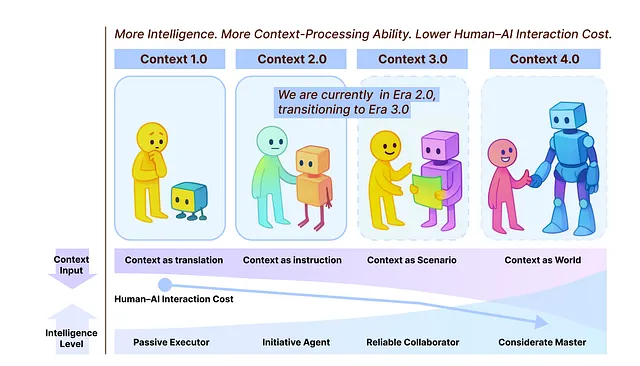
How Context Engineering has changed over time? — [ Source ]
Remember learning to type commands into MS-DOS in the 90s? For decades, we accepted this as normal. If we wanted the computer to do something, we should learn its language, follow its rules. We should structure our thoughts the way they need them structured.
We called that a user-friendly design. Looking back, it was anything but.
Era 1.0: The Age of Human Adaptation (1990s-2020):
Section titled “Era 1.0: The Age of Human Adaptation (1990s-2020):”In 2005, when you’re building a location-aware mobile app and your system needs to know where users are, what they’re doing, and maybe what they need next. You would build elaborate sensor frameworks that collect GPS location, time stamps, predefined activity states like “ at home ”, “ at work ”, “ commuting ”. Every possibility is manually enumerated. Every edge case is explicitly handled. Your users would have to use check boxes, fill forms, and select from dropdown menus.
The paradox of Era 1.0 was that we talked about context-aware systems while building systems that were fundamentally context-blind. They could sense location but not understand why you were there. They could track time but not grasp what you were trying to accomplish.
In Era 1.0, designers weren’t really designers. We were intention translators. Your job was to take the messy, high-entropy chaos of human thought and compress it into something a machine could process.
Era 2.0: The Great Reversal (2020-Present):
Section titled “Era 2.0: The Great Reversal (2020-Present):”Then everything flipped in early 2023. Machines started speaking human language. Three shifts define this new era, and they’re more profound than they initially appear:
1. Context acquisition became richer — and messier
Era 1.0 sensors gave you clean, structured data: latitude/longitude pairs, timestamps, and discrete states.
In Era 2.0, you can throw anything at the system. Rambling text. Blurry photos. Half-finished thoughts. Video clips. Voice notes recorded at 3 AM when you barely sound coherent. The machine doesn’t complain. It doesn’t demand you restructure your input. It just… figures it out. It’s because of improved entropy tolerance. Modern systems can work with high-entropy information directly. They don’t need you to compress your intentions first.
2. Raw context became acceptable
In Era 1.0, preprocessing was everything. You couldn’t feed raw GPS data into your app logic; you had to classify it first- home, work, shopping. Every coordinate is reduced to a category.
Era 2.0 systems keep context closer to its original form. They work with the messiness. They can process “ I’m at that coffee shop near the park where we met last Tuesday ” without you having to translate it into structured location data first.
3. Understanding shifted from passive to active
The early context-aware systems glorified if-then rules. “If the user enters the conference room, then silence the phone.”, “If the calendar shows ‘meeting,’ then activate do-not-disturb”.
Era 2.0 systems try to understand what you’re doing and why. They don’t just react to context, they collaborate with it. The system analyzes your previous sections, understands your argument structure, and suggests what comes next.
This is the leap from context-aware to context-cooperative.
How to manage Context?
Section titled “How to manage Context?”Good context engineering is not only about collecting information. It is also about what we do with it afterward.
A strong processing approach sets the base for everything that follows, like interpretation, compression, and retrieval. It helps systems focus on what is important.
Textual Context Processing (How should raw text context be processed to get the best results?)
Section titled “Textual Context Processing (How should raw text context be processed to get the best results?)”Storing everything as-is is often not enough. Multi-turn conversations and logs grow quickly. Without structure, they become hard to use. Below are several common ways teams process textual context, along with the trade-offs each one brings.
Marking context with timestamps.
One simple approach is to attach a timestamp to each piece of context. This preserves the order in which information appears. It is easy to implement and maintain.
But timestamps only capture time. They add no meaning or semantic structure. Finding relevant past information becomes slower as interactions pile up. Over time, the context grows exponentially, which creates problems for both storage and reasoning.
Tagging context by function and meaning.
Another approach is to label each entry with a role. For example, a goal, decision, or action. This makes context easier to read and interpret. Some systems go further and add multiple tags, such as priority, source, or confidence. This structure improves retrieval and organization. It brings clarity. Still, it can be rigid. Predefined tags may limit flexible reasoning.
Compression using question–answer pairs.
In this method, context is rewritten as clear question–answer pairs. This works well when fast lookup is the goal like search systems, FAQ-style tools. This makes the method less useful for tasks that need a holistic view, such as summarization or multi-step reasoning.
Compression using hierarchical notes.
Here, information is organized like a tree. High-level ideas at the top with the details branching below. But hierarchy mainly shows grouping, not logic. Relationships like cause and effect are often missing. These notes rarely capture how understanding changes, such as when ideas are revised or new insights appear.
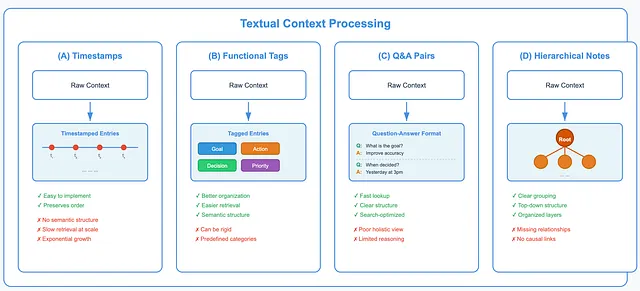
Textual Context Processing — Image by Author
So, each of these methods solves a problem, but none solves all of them. Choosing the right one depends on what the system needs to remember and how it needs to think.
Multi-Modal Context Processing
Section titled “Multi-Modal Context Processing”Context in modern AI systems is no longer just text. It now includes images, audio, video, code, sensor signals, and even environmental states. As systems interact with real or simulated worlds, they must combine all of this information into a single, coherent understanding.
But the challenge is that different modalities behave very differently. Text is discrete and sequential. Images are dense and spatial. Audio unfolds over time. Video combines several of these at once. The question becomes: how can systems align, compare, and reason across such diverse forms of context?
There are several common strategies that could be used.
Mapping multimodal inputs into a shared vector space.
One widely used approach is to transform different modalities into a common embedding space. Text, images, and video are each processed by their own encoders. These outputs are then projected into a shared vector space with a fixed size.
In this space, meaning becomes comparable. Content that is semantically related ends up close together, even if it comes from different modalities. Unrelated content is pushed farther apart. This makes cross-modal comparison and retrieval much easier.
Combining modalities through shared self-attention.
Another strategy processes all modalities together using a single Transformer model. After projection, tokens from text, images, and other inputs are fed into the same self-attention layers.
This allows tokens to attend to one another directly. A phrase can align with a specific region of an image. A visual detail can influence how text is interpreted. This is deeper than simply stitching embeddings together. It supports fine-grained reasoning across modalities.
Using cross-attention between modalities.
A third approach relies on cross-attention. One modality actively queries another. For example, text features can act as queries, while image features serve as keys and values.
This setup allows targeted information retrieval across modalities. The model can focus on exactly what it needs. Cross-attention can be added as a separate module or embedded directly into the main architecture.
There is a limitation, though. These designs usually require predefined interaction paths between modalities. Humans do not work this way. The human brain integrates signals fluidly, without fixed mappings.
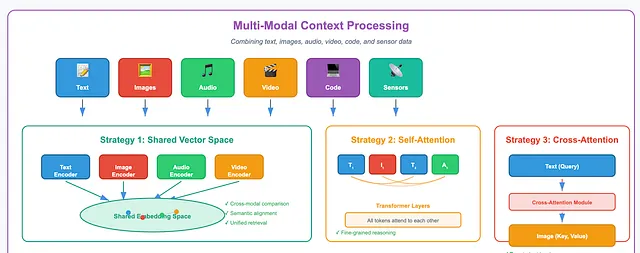
Multi-Modal Context Processing — Image by Author
How to Organise the Context collected?
Section titled “How to Organise the Context collected?”Managing context across time is a core challenge. Some information matters right now. Some needs to be stored for later. Some should last across sessions.
So, memory should be layered. Separating memory by time scale helps systems stay responsive without losing what matters.
Many systems already follow this idea. When working with very long inputs, key plans or summaries are stored outside the context window so they are not lost. The system retrieves them only when needed.
For clarity, we describe a two-layer model here, though real systems often use more.
1. Memory Management
Section titled “1. Memory Management”Short-term memory.
Short-term memory holds context that is highly relevant right now. It is selected based on recency. Filtering may be done using rules, heuristics, or human judgment. This memory is fast and fragile.
Long-term memory.
Long-term memory stores context that remains important over time. It is more abstract. Often compressed. It persists across sessions. Only information that is both important and no longer recent is promoted to this layer. The goal is stability, not speed.
Memory transfer.
Information moves from short-term to long-term memory through a consolidation process. This mirrors how humans reinforce memory over time.
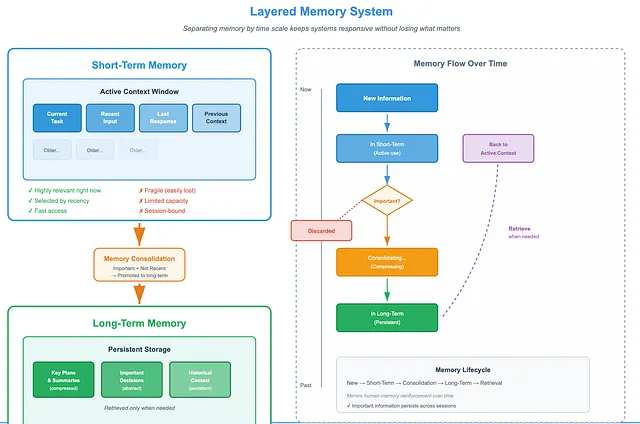
Memory Management — Image by Author
2. Context Isolation
Section titled “2. Context Isolation”Another strategy for managing context is isolation.
Subagents.
Subagents offer a way to work around context limits while reducing noise. Each subagent operates with its own isolated context window, system prompt, and tool access. When a task fits a subagent’s role, the main system delegates it.
The benefit is clear. The main context stays clean. Specialized work happens elsewhere. This improves reliability and makes system behavior easier to understand.
Isolation can be applied in many ways. By function, such as analysis or execution. By hierarchy, such as planning and review. Each unit gets only what it needs. Nothing more.
Some systems go further. They plan first, then decide what information to gather. Subagents may work in parallel. The main agent summarizes results and chooses next steps. This feedback loop helps the system converge on better outcomes.
Lightweight references.
Context isolation often relies on storing large data externally. The model only sees references. Full details are fetched on demand.
For example, bulky outputs may live in a sandbox. The context window contains only a pointer. Schema-based state objects work the same way. Large files stay outside. Only key fields are exposed.
This keeps the context window small and focused. At the same time, nothing is truly lost. Full context is still available when needed.
In practice, isolation and lightweight references work together. They reduce token usage, prevent pollution, and support more scalable context management.
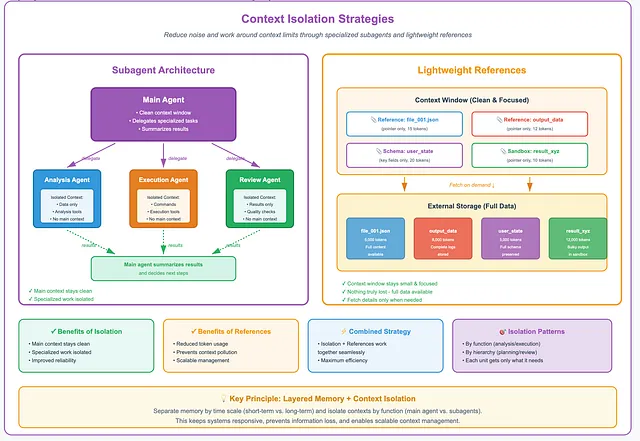
Context Abstraction (How to Compact the Stored Context?)
Section titled “Context Abstraction (How to Compact the Stored Context?)”To scale, agents need a way to digest what they see. This is where context abstraction comes in.
Context abstraction turns raw input into compact, structured representations. It’s called self-baking.
The agent processes its own experience and converts it into lasting knowledge.
This idea mirrors how humans think. Repeated experiences turn into general knowledge. Frequent actions become habits. Without self-baking, an agent only remembers. With it, the agent learns.
Below are several common self-baking designs used in today’s systems.
1. Using Hierarchical Memory Architectures
Section titled “1. Using Hierarchical Memory Architectures”Most systems are based on a simple idea that not all context should live at the same level.
Hierarchical memory organizes information by abstraction. Raw context sits at the bottom. As more context arrives, these details are summarized into higher-level representations.
This design prevents overload. It also aligns well with short-term and long-term memory. Short-term memory holds raw and recent context. Long-term memory stores more stable and abstract knowledge.

Hierarchical Memory Architectures — Image by Author
2. Adding Natural-Language Summaries
Section titled “2. Adding Natural-Language Summaries”The system periodically generates short text summaries that describe what has happened. A chatbot, for example, may store the full conversation and also maintain a paragraph summarizing recent turns.
As summaries accumulate, systems may summarize the summaries. Older ones may be merged, shortened, or dropped based on age or importance.
This approach is simple, flexible, and easy to implement. But it has limits. Plain text summaries lack structure. Relationships between events are often implicit. Deeper reasoning becomes difficult.

Natural-Language Summaries — Image by Author
3. Extracting Key Facts Using a Fixed Schema
Section titled “3. Extracting Key Facts Using a Fixed Schema”Some systems go further. They keep the raw context, but also extract key facts into a structured format.
This structure can take many forms, like an entity graph, event records, and task trees. Each one highlights different aspects of the context.
For example, an entity map may track people, objects, and places. It stores their properties and relationships. Event records break actions into time, cause, and outcome. Task trees split goals into subtasks.
This structure supports stronger reasoning. The system can query specific facts, compare states, and track dependencies. The downside is complexity. Multiple memory layers must stay consistent. Designing reliable extractors that populate these schemas remains hard.
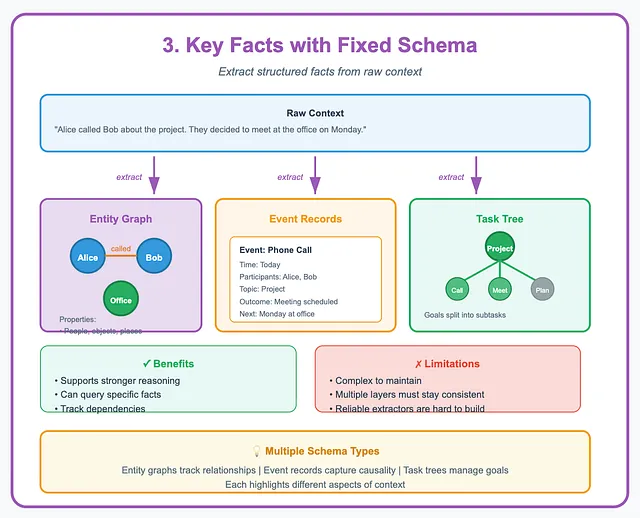
Extracting Key Facts Using a Fixed Schema — Image by Author
4. Compressing Context into Semantic Vectors
Section titled “4. Compressing Context into Semantic Vectors”Here, context is encoded into dense numerical vectors, called embeddings. These vectors capture semantic similarity. Related ideas end up close together. Over time, older vectors can be merged or pooled into more abstract ones. These compressed representations become stable semantic memory.
This method is efficient, scalable, and well-suited for search and similarity matching. But it comes with a trade-off. Vector memories are not human-readable. Inspecting or editing specific details is difficult. Each abstraction strategy makes a different choice. Text summaries favor simplicity. Schemas favor precision. Vectors favor scale.
In practice, strong systems often combine several of these ideas. Self-baking is not a single technique. It is more like an architecture that turns growing context into usable knowledge.
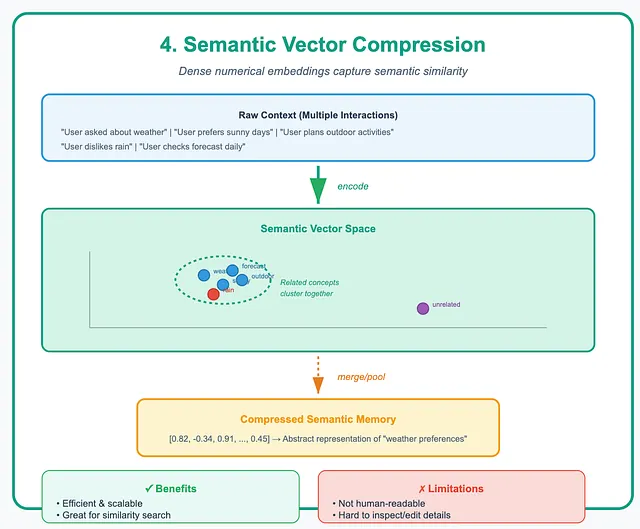
Compressing Context into Semantic Vectors — Image by Author
How to use the Context Effectively?
Section titled “How to use the Context Effectively?”Collecting and storing context is only half the story. The real value appears when context is used well within a system, across systems and more importantly, ahead of user requests.
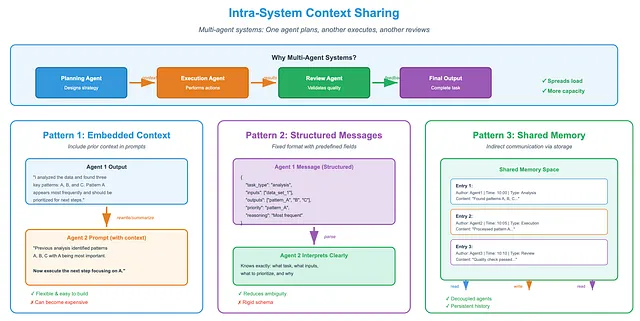
1. Intra-System Context Sharing
Section titled “1. Intra-System Context Sharing”Many modern applications use multiple agent frameworks. Each agent handles part of a larger task. One agent plans, another executes, and another reviews. This setup works because it spreads the load. Together, the agents can process far more information than a single agent could manage alone.
But how do agents share context? In a multi-agent system, agents must pass information clearly and reliably. One agent’s output often becomes another agent’s input. If context is vague or messy, collaboration breaks down. To avoid this, systems use several common sharing patterns.
Intra-System Context Sharing — Image by Author
Embedding previous context into prompts:
The simplest method is to include prior context directly in the next agent’s prompt. Often, the context is rewritten or summarized to make it easier to read.
For example, one agent may produce a short text summary of its reasoning. The next agent reads that summary and continues the task. This pattern is common in sequential agent systems, where prompts act as the communication channel.
This approach is flexible and easy to build. But it can become expensive as prompts grow longer.
Exchanging structured messages:
Another approach uses structured messages instead of free text. Agents exchange data in fixed formats with predefined fields, such as task type, inputs, outputs, and reasoning steps.
Because the structure is explicit, the receiving agent knows exactly how to interpret the message. This reduces ambiguity and makes coordination more reliable. The trade-off is rigidity. Changes to the schema require careful updates.
Using shared memory for indirect communication.
Agents can also communicate indirectly through shared memory. Instead of sending messages, they read from and write to a common storage space.
Each memory entry usually includes metadata like who wrote it, when, and what kind of information it holds. Agents check this space periodically to find updates.
Shared memory can be organized in different ways. It could be a simple pool of memory blocks, a blackboard divided by topic or task, or a graph that tracks reasoning steps and dependencies.
Graph-based memory is especially useful for complex workflows. Each node represents a step or insight. Edges capture how steps depend on one another. This makes it easier to resume work, reuse results, and follow multi-step reasoning.
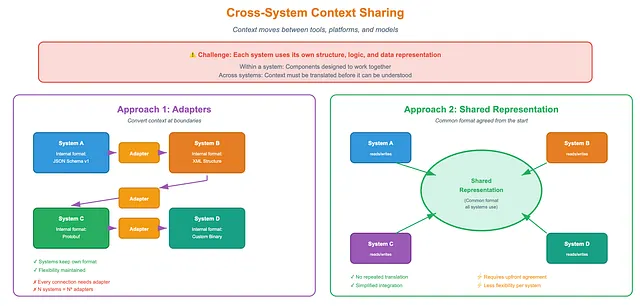
2. Cross-System Context Sharing
Section titled “2. Cross-System Context Sharing”A system does not always work alone. In practice, context often needs to move across system boundaries, between tools, between platforms and between models.
Within a single system, sharing is easier. Components are designed to work together. Across systems, things get harder. Each system may use its own structure, logic, and data representation. Context must be translated before it can be understood.
Two main approaches are common.
- Using adapters to convert context.
Each system keeps its own internal format. Adapters handle translation at the boundaries. This gives systems flexibility, but it comes at a cost. Every new connection needs a new adapter. - Using a shared representation.
Another option is to agree on a common format from the start. All systems read and write the same representation. This avoids repeated translation and simplifies integration.
Cross-System Context Sharing — Image by Author
Shared representations take several forms:
Standard data formats: Systems may agree on JSON schemas or APIs. This provides precision and consistency.
Human-readable summaries: Systems can exchange short natural-language descriptions. These are easy to generate and interpret, though less precise.
Semantic vectors. Context can be shared as embeddings that capture meaning numerically.
Each choice has trade-offs. Structured formats are clear but strict. Natural language is flexible but ambiguous. Vectors are powerful but opaque. The right choice depends on the systems involved and the goal of sharing.
Context Selection for Understanding (What context should be selected?)
Section titled “Context Selection for Understanding (What context should be selected?)”Even with large context windows, models cannot use everything at once. Input quality matters more than quantity. So a key question arises. What context should be selected now?
Context may come from memory, tools, scratchpads, or retrieval systems. But not all of it helps. Irrelevant or noisy information can slow reasoning and increase cost. Too much context can be just as harmful as too little.
This makes context selection a form of attention before attention. Several factors guide this process.
Semantic relevance.
Information that is similar in meaning to the current task is more likely to be useful. This is often handled with embeddings and nearest-neighbor search, which can find related content even without exact keyword matches.
Logical dependency.
Some context is required because the current step depends on earlier decisions or outputs. Systems may explicitly track these dependencies so they can retrieve only the relevant reasoning chain.
Recency and frequency.
Recent information matters more than old information. Frequently used information matters more than rarely used information.
Overlapping information.
If multiple entries say the same thing, older or weaker ones can be removed or merged.
User preference and feedback.
Over time, systems learn what a user values. They adjust memory importance based on interaction patterns and feedback, explicit or implicit.

Context Selection for Understanding — Image by Author
How to preserve and update the Context overtime?
Section titled “How to preserve and update the Context overtime?”People are shaped by experience, interaction and context. If AI systems are meant to work alongside humans over long periods, their context must also last.
Since context is needed lifelong, how should it be stored and updated so it stays useful, coherent, and safe?
At this scale, simple storage is not enough. Lifelong context demands memory systems that can change over time. Systems that understand meaning. One thing is sure though, naive extensions of today’s designs break down under real-world complexity.
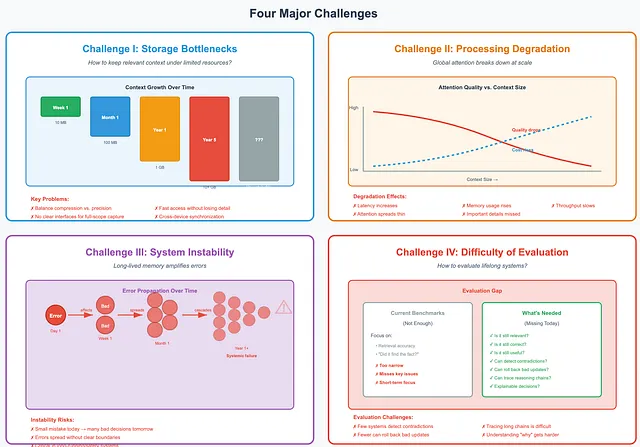
Challenge I: Storage Bottlenecks
Section titled “Challenge I: Storage Bottlenecks”The first challenge is storage. How do we keep as much relevant context as possible under limited resources? There is no single answer yet. Systems must balance compression with precision. They must support fast access without losing detail. They must scale without collapsing.
We still lack clear interfaces and infrastructure for capturing context at full scope. Especially over years and across devices.
Challenge II: Processing Degradation
Section titled “Challenge II: Processing Degradation”Scale creates another problem. Attention.
Most current models rely on global attention. As context grows, this becomes expensive, latency increases, memory usage rises and throughput slows. Quality also drops as attention spreads thin. Important details are missed. Long-range relationships fade.
Challenge III: System Instability
Section titled “Challenge III: System Instability”Long-lived memory amplifies errors. A small mistake today can affect many decisions tomorrow. Without clear boundaries and validation, errors spread.
This is especially risky in long-running or safety-critical systems. More memory does not always mean more reliability. Sometimes, it means the opposite.
Challenge IV: Difficulty of Evaluation
Section titled “Challenge IV: Difficulty of Evaluation”Evaluating lifelong systems is hard. Most benchmarks focus on retrieval. Did the system find the right fact? That is not enough.
We also need to ask: Is the information still relevant? Still correct? Still useful?
Few systems can detect contradictions. Fewer can roll back bad updates. Tracing long reasoning chains remains difficult. As memory grows, understanding why a system reached a decision becomes harder.
Challenges in preserving and updating the Context overtime — Image by Author
Lifelong context engineering cannot be solved by larger context windows or better retrieval alone. It requires a new way of thinking.
We need something closer to a semantic operating system. One that grows over time. One that manages meaning, not just data. Such a system would store context at scale. It would also manage memory actively by adding, updating and forgetting. Just as humans do. And it would be able to explain itself. Tracing decisions. Correcting errors. Showing how conclusions were reached.
Engineering Practices for Effective Context Engineering
Section titled “Engineering Practices for Effective Context Engineering”As agents move from demos to real systems, small engineering choices start to matter a lot. Performance, cost, and reliability are often decided not by the model itself, but by how context is handled around it. Several practical patterns are now emerging.
KV Caching
Section titled “KV Caching”Key–value (KV) caching has become essential for running agents efficiently. This is based on a simple idea that when the model processes tokens, it stores their attention keys and values. If those tokens appear again, the system does not recompute them. This can save a lot of time and money. But only if the cache is used correctly.
A few practices help improve it:
- Keep prefix prompts stable. Even small changes, like adding a timestamp at the top of a prompt, can invalidate the entire cache.
- Use append-only updates. Past content should never be edited or reordered. Inconsistent serialization breaks reuse.
- Insert cache checkpoints when needed. Some serving systems do not handle prefix caching automatically. In those cases, checkpoints must be added by hand and placed carefully.
Cache warm-up also helps. Systems often preload contexts they expect to need soon. This predictive loading reduces latency during actual use.
Tool Design
Section titled “Tool Design”While designing tools, follow the engineering best practices below.
Clear descriptions matter.
Each tool needs a precise purpose. Vague or overlapping descriptions confuse models and lead to failures. Well-structured descriptions reduce ambiguity and improve reliability. In some systems, models even help refine these descriptions over time.
Tool count matters too.
Large tool sets make agents less reliable. Selecting the right tool becomes harder and performance drops. Dynamically adding tools during a session can also break KV caching and confuse references to earlier actions.
In practice, smaller and more stable tool sets work better. A common approach is to keep the list fixed and enforce constraints during decoding, such as blocking invalid choices.
Context Contents
Section titled “Context Contents”Agents should not hide their mistakes. Keeping errors in the context allows the model to see what went wrong. This is important for learning corrective behavior. If failures disappear, the model cannot improve.
There is another subtle issue. Traditional few-shot prompting can backfire in agent settings. When the context contains many similar action–observation pairs, the model tends to repeat the same behavior.
One solution is controlled variation. Small changes in phrasing, formatting, or ordering can break repetition. These variations refocus attention and reduce overgeneralization, leading to more robust behavior.
Multi-Agent Systems
Section titled “Multi-Agent Systems”Experience with multi-agent systems shows a few recurring rules.
The lead agent plays a key role. It breaks the problem into subtasks. It assigns each task with clear goals, expected outputs, tool guidance, and boundaries.
Agents also struggle to estimate workload. Simple rules help. Easy tasks may need one agent. Harder tasks may need several.
Search works best in stages. Start broad. Then narrow down. Finally, analyze deeply. Asking agents to write out their reasoning often improves accuracy and efficiency.
Small but Useful Tricks
Section titled “Small but Useful Tricks”Many systems keep a todo.md file during long tasks. It lists subgoals and marks progress.
But long tasks create another problem. Models forget earlier goals. When updating the todo list, restate the goals in natural language. This pulls them back into the recent context and keeps them within the model’s active attention.
Closing Thoughts:
Section titled “Closing Thoughts:”Context engineering isn’t going away. It’s becoming the invisible architecture behing successful AI systems.
Most people think we’re heading toward a future where all this complexity disappears. Where you just talk to the AI and it magically understands everything. Maybe. But I’m not holding my breath.
But the uncomfortable truth is… Every time we solve one context problem, we unlock three new ones.
We solved structured input requirements. Now we’re drowning in unstructured data. We solved single-turn interactions. Now we’re wrestling with memory management across years. We solved keyword matching. Now we’re debugging why the model retrieved the wrong semantic cluster.
The problems don’t disappear. They just move up the stack.
If you’re building AI systems today, whether that’s a RAG pipeline, an agent framework I would suggest you to start thinking in systems, not prompts. Everyone can craft a decent prompt. The real differentiation is in how you architect context flow across multiple agents, how you handle memory decay, how you balance retrieval precision with recall.
Treat context as infrastructure. You wouldn’t build a production app without thinking about databases, caching, and API design. Context deserves the same level of architectural rigor.
If you take nothing else from this article, remember this:
Your AI system is only as good as its context architecture.
AI Innovator & ML Solutions Architect | 12+ years in DataScience, ML and AI | Inventor | 3 patents | Believes in life long learning
More from Vivedha Elango and Level Up Coding
Section titled “More from Vivedha Elango and Level Up Coding”Recommended from Medium
Section titled “Recommended from Medium”[
See more recommendations